
La vaca cega desconfiada
_FRASE_TOP
| 24-05-2024 (721 ) | Categoria: Articles |
La NVIDIA A100 Ă©s una excel·lent GPU per a l'aprenentatge profund. EstĂ dissenyat especĂficament per a centres de dades i aplicacions professionals, incloses tasques d'aprenentatge profund. Aquestes sĂłn algunes de les raons per les quals l'A100 es considera una opciĂł poderosa per a l'aprenentatge profund:
- Arquitectura d'Ampere: L'A100 es basa en l'arquitectura Ampere de NVIDIA, que aporta millores significatives de rendiment respecte a les generacions anteriors. Compta amb nuclis de tensor avançats que acceleren els cà lculs d'aprenentatge profund, permetent temps d'entrenament i inferència més rà pids.
- Alt rendiment: L'A100 és una GPU d'alt rendiment amb un gran nombre de nuclis CUDA, nuclis de tensor i amplada de banda de memòria. Pot manejar models complexos d'aprenentatge profund i grans conjunts de dades, oferint un rendiment excepcional per a cà rregues de treball d'entrenament i inferència.
- Entrenament millorat de precisió mixta: L'A100 admet entrenament de precisió mixta, que combina diferents precisions numèriques (com FP16 i FP32) per optimitzar el rendiment i la utilització de memòria. Això pot accelerar l'entrenament d'aprenentatge profund mantenint la precisió.
- Alta capacitat de memòria: L'A100 ofereix una capacitat de memòria massiva de fins a 80 GB, grà cies a la seva tecnologia de memòria HBM2. Això permet processar models a gran escala i manejar grans conjunts de dades sense topar amb limitacions de memòria.
- Capacitat de GPU de mĂşltiples instĂ ncies (MIG): L'A100 introdueix la tecnologia GPU de mĂşltiples instĂ ncies (MIG), que permet dividir una sola GPU en mĂşltiples instĂ ncies mĂ©s petites, cadascuna amb recursos de cĂ lcul dedicats. Aquesta caracterĂstica permet una utilitzaciĂł eficient de la GPU per executar diverses cĂ rregues de treball d'aprenentatge profund simultĂ niament.
Aquestes funcions fan que NVIDIA A100 sigui una opció excepcional per a tasques d'aprenentatge profund. Proporciona capacitats avançades d'IA d'alt rendiment, gran capacitat de memòria i una utilització eficient dels recursos computacionals, tots els quals són crucials per entrenar i executar xarxes neuronals profundes complexes.
La NVIDIA RTX A6000 Ă©s una potent GPU adequada per a aplicacions d'aprenentatge profund. El RTX A6000 es basa en l'arquitectura Ampere i forma part de la lĂnia de GPU professional de NVIDIA. Ofereix un rendiment excel·lent, funcions avançades d'IA i una gran capacitat de memòria, cosa que el fa adequat per entrenar i executar xarxes neuronals profundes. Aquestes sĂłn algunes caracterĂstiques clau del RTX A6000 que el converteixen en una bona opciĂł per a l'aprenentatge profund:
- Arquitectura d'Ampere: El RTX A6000 es basa en l'arquitectura Ampere de NVIDIA, que ofereix millores significatives de rendiment respecte a les generacions anteriors. Compta amb nuclis de tensor avançats per a l'acceleració de la IA, capacitats millorades de traçat de raigs i augment de l'amplada de banda de memòria.
- Alt rendiment: El RTX A6000 ofereix un alt nombre de nuclis CUDA, nuclis de tensor i nuclis de traçat de raigs, el que resulta en un rendiment d'aprenentatge profund rà pid i eficient. Pot manejar models d'aprenentatge profund a gran escala i cà lculs complexos necessaris per entrenar xarxes neuronals.
- Gran capacitat de memòria: El RTX A6000 ve amb 48 GB de memòria GDDR6, proporcionant un ampli espai de memòria per emmagatzemar i processar grans conjunts de dades. Tenir una gran capacitat de memòria és beneficiós per entrenar models d'aprenentatge profund que requereixen una quantitat significativa de memòria.
- CaracterĂstiques de la IA: El RTX A6000 inclou nuclis de tensor dedicats, que acceleren els cĂ lculs d'IA i permeten l'entrenament de precisiĂł mixta. Aquests nuclis tensorials poden accelerar significativament les cĂ rregues de treball d'aprenentatge profund realitzant operacions com multiplicacions de matrius a un ritme accelerat.
Tot i que el RTX A6000 estĂ dissenyat principalment per a aplicacions professionals, sens dubte es pot utilitzar eficaçment per a tasques d'aprenentatge profund. El seu alt rendiment, capacitat de memòria i caracterĂstiques especĂfiques de la IA el converteixen en una opciĂł poderosa per entrenar i executar xarxes neuronals profundes.
La NVIDIA GeForce RTX 4090 és una potent targeta grà fica de qualitat del consumidor que es pot utilitzar per a l'aprenentatge profund, però no és tan adequada per a aquesta tasca com GPU professionals com la Nvidia A100 o la RTX A6000.
Avantatges de la RTX 4090 per a l'aprenentatge profund:
- Elevat nombre de nuclis CUDA: El RTX 4090 disposa de 16384 nuclis CUDA, que sĂłn les unitats de processament encarregades de realitzar cĂ lculs d'aprenentatge profund.
- Ample de banda d'alta memòria: El RTX 4090 té una amplada de banda de memòria d'1 TB/s, que li permet transferir dades des de i cap a la memòria rà pidament.
- Gran capacitat de memòria: El RTX 4090 té 24 GB de memòria GDDR6X, que és suficient per entrenar models d'aprenentatge profund de mida petita i mitjana.
- Suport per CUDA i cuDNN: El RTX 4090 estĂ totalment suportat per les biblioteques CUDA i cuDNN de Nvidia, que sĂłn essencials per desenvolupar i optimitzar models d'aprenentatge profund.
Desavantatges del RTX 4090 per a l'aprenentatge profund:
- Menor nombre de nuclis tensorials: El RTX 4090 només té 128 nuclis tensorials, que són unitats de maquinari especialitzades dissenyades per accelerar operacions matricials habituals en algorismes d'aprenentatge profund. Les GPU professionals com l'A100 i l'A6000 tenen significativament més nuclis tensorials, proporcionant un avantatge de rendiment per a tasques d'aprenentatge profund.
- Menor capacitat de memòria: Els 24 GB de memòria del RTX 4090 són suficients per a models petits i mitjans, però pot ser limitant per entrenar models grans o treballar amb conjunts de dades grans.
- Manca de suport NVLink: El RTX 4090 no admet NVLink, que és una tecnologia d'interconnexió d'alta velocitat que permet connectar múltiples GPU entre si per escalar el rendiment. Això fa que el RTX 4090 sigui menys adequat per construir clústers d'aprenentatge profund a gran escala.
En general, la RTX 4090 és una GPU capaç d'aprendre profundament, però no és tan adequada per a aquesta tasca com les GPU professionals com la Nvidia A100 o la RTX A6000. Si sou seriós sobre l'aprenentatge profund i necessiteu el mà xim rendiment possible, una GPU professional és una millor opció. Tanmateix, si teniu pressupost o només necessiteu formar models petits i mitjans, el RTX 4090 pot ser una bona opció.
La NVIDIA A40 és una GPU capaç per a tasques d'aprenentatge profund. Tot i que està dissenyat principalment per a centres de dades i aplicacions professionals, també es pot utilitzar eficaçment per a cà rregues de treball d'aprenentatge profund. Aquestes són algunes de les raons per les quals l'A40 és adequat per a l'aprenentatge profund:
- Arquitectura d'Ampere: L'A40 es basa en l'arquitectura Ampere de NVIDIA, que aporta millores significatives de rendiment i funcions especĂfiques d'IA. Inclou nuclis tensorials per a cĂ lculs accelerats d'aprenentatge profund, el que resulta en temps d'entrenament i inferència mĂ©s rĂ pids.
- Alt rendiment: L'A40 ofereix un alt nombre de nuclis CUDA i nuclis de tensor, proporcionant una potència de cà lcul substancial per a tasques d'aprenentatge profund. Pot manejar models a gran escala i cà lculs complexos necessaris per entrenar xarxes neuronals profundes.
- Capacitat de memòria: L'A40 ve amb 48 GB de memòria GDDR6, proporcionant un ampli espai per emmagatzemar i processar grans conjunts de dades. Una capacitat de memòria suficient és crucial per entrenar models d'aprenentatge profund que requereixen un ampli accés a memòria.
- IA i optimitzaciĂł de l'aprenentatge profund: L'A40 es beneficia de la pila de programari d'aprenentatge profund de NVIDIA, inclosos CUDA, cuDNN i TensorRT. Aquestes biblioteques de programari estan optimitzades per a cĂ rregues de treball d'aprenentatge profund, garantint una utilitzaciĂł eficient dels recursos de la GPU i oferint un alt rendiment.
- Compatibilitat i suport: L'A40 Ă©s compatible amb marcs d'aprenentatge profund populars, com ara TensorFlow, PyTorch i MXNet. EstĂ recolzat per l'extens ecosistema de NVIDIA i el suport per a desenvolupadors, cosa que facilita la integraciĂł en els fluxos de treball d'aprenentatge profund existents.
Tot i que Ă©s possible que l'A40 no ofereixi el mateix nivell de rendiment que les GPU de gamma alta com l'A100, encara proporciona una potència de cĂ lcul substancial i funcions especĂfiques d'IA que el converteixen en una opciĂł adequada per a tasques d'aprenentatge profund. Ofereix un equilibri entre rendiment i assequibilitat, cosa que el converteix en una opciĂł prĂ ctica per a organitzacions i investigadors que treballen en projectes d'aprenentatge profund.
La NVIDIA V100 Ă©s una excel·lent GPU per a l'aprenentatge profund. EstĂ dissenyat especĂficament per a cĂ rregues de treball de computaciĂł i IA d'alt rendiment, cosa que el fa adequat per a tasques d'aprenentatge profund. Aquestes sĂłn algunes de les raons per les quals el V100 es considera una opciĂł poderosa per a l'aprenentatge profund:
- Arquitectura Volta: El V100 es basa en l'arquitectura Volta de NVIDIA, que ofereix avenços significatius en rendiment i funcions especĂfiques d'IA. Inclou nuclis tensorials, que acceleren els cĂ lculs d'aprenentatge profund, el que resulta en temps d'entrenament i inferència mĂ©s rĂ pids.
- Alt rendiment: El V100 és una GPU d'alt rendiment amb un gran nombre de nuclis CUDA, nuclis tensorials i un ample de banda d'alta memòria. Pot manejar models complexos d'aprenentatge profund i grans conjunts de dades, oferint un rendiment excepcional per a cà rregues de treball d'entrenament i inferència.
- Capacitat de memòria: El V100 ofereix una generosa capacitat de memòria de fins a 32 GB amb tecnologia de memòria HBM2, proporcionant espai suficient per emmagatzemar i processar grans conjunts de dades. Això és crucial per a tasques d'aprenentatge profund que requereixen un ampli accés a memòria.
- Entrenament de precisió mixta: El V100 admet entrenament de precisió mixta, permetent una combinació de cà lculs de menor precisió (com el FP16) i de major precisió (com el FP32). Això permet un entrenament més rà pid mantenint nivells acceptables de precisió.
- Interconnexió NVLink: El V100 compta amb NVLink, una tecnologia d'interconnexió d'alta velocitat que permet que múltiples GPU treballin juntes en un sol sistema. Això permet configuracions multi-GPU escalables per a un rendiment encara més alt en aplicacions d'aprenentatge profund.
La NVIDIA V100 ha estat Ă mpliament adoptat en centres de dades i entorns de computaciĂł d'alt rendiment per a tasques d'aprenentatge profund. La seva potent arquitectura, alt rendiment i caracterĂstiques especĂfiques de la IA el converteixen en una opciĂł fiable per entrenar i executar xarxes neuronals profundes complexes. Val la pena assenyalar que el V100 pot ser mĂ©s comĂş en entorns professionals i empresarials a causa del seu preu, però continua sent una GPU altament capaç per a l'aprenentatge profund.
| NVIDIA A100 | RTX A6000 | RTX 4090 | NVIDIA A40 | NVIDIA V100 | |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
| Arquitectura | Ampere | Ampere | Ada Lovelace | Ampere | Volta |
| Llançar | 2020 | 2020 | 2022 | 2020 | 2017 |
| Nuclis CUDA | 6,912 | 10,752 | 16,384 | 10,752 | 5,120 |
| Nuclis tensorials | 432, Gen 3 | 336, Gen 3 | 512, Gen 4 | 336, Gen 3 | 640, Gen 1 |
| Rellotge d'impuls (GHz) | 1.41 | 1.41 | 2.23 | 1.10 | 1.53 |
| FP16 TFLOPs | 78 | 38.7 | 82.6 | 37 | 28 |
| FP32 TFLOPs | 19.5 | 38.7 | 82.6 | 37 | 14 |
| FP64 TFLOPs | 9.7 | 1.2 | 1.3 | 0.6 | 7 |
| Velocitat de pĂxels | 225.6 GPixel/s | 201.6 GPixel/s | 483.8 GPixel/s | 194.9 GPixel/s | 176.6 GPixel/s |
| Taxa de textura | 609.1 GTexel/s | 604.8 GTexel/s | 1290 GTexel/s | 584.6 GTexel/s | 441.6 GTexel/s |
| Memòria | 40/80GB HBM2e | 48GB GDDR6 | 24GB GDDR6X | 48GB GDDR6 | 16/32GB HBM2 |
| Ample de banda de memòria | 1,6 TB/s | 768 GB/s | 1 TB/s | 672 GB/s | 900 GB/s |
| Interconnecten | NVLink | NVLink | N.P. | NVLink | NVLink |
| TDP | 250W/400W | 250W | 450W | 300W | 250W |
| Transistors | 54.2B | 54.2B | 76B | 54.2B | 21.1B |
| FabricaciĂł | 7nm | 7nm | 4 nm | 7nm | 12 nm |
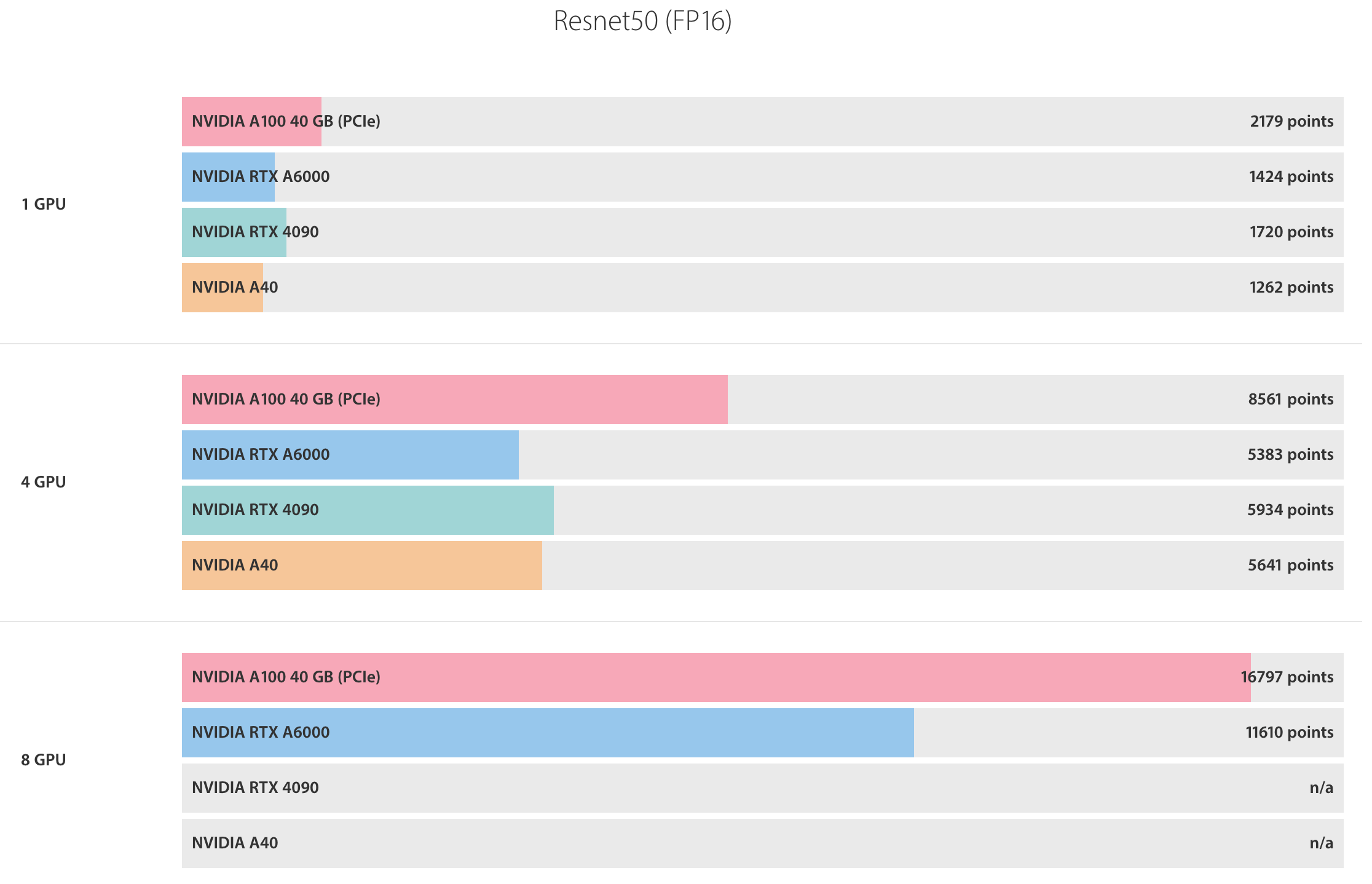
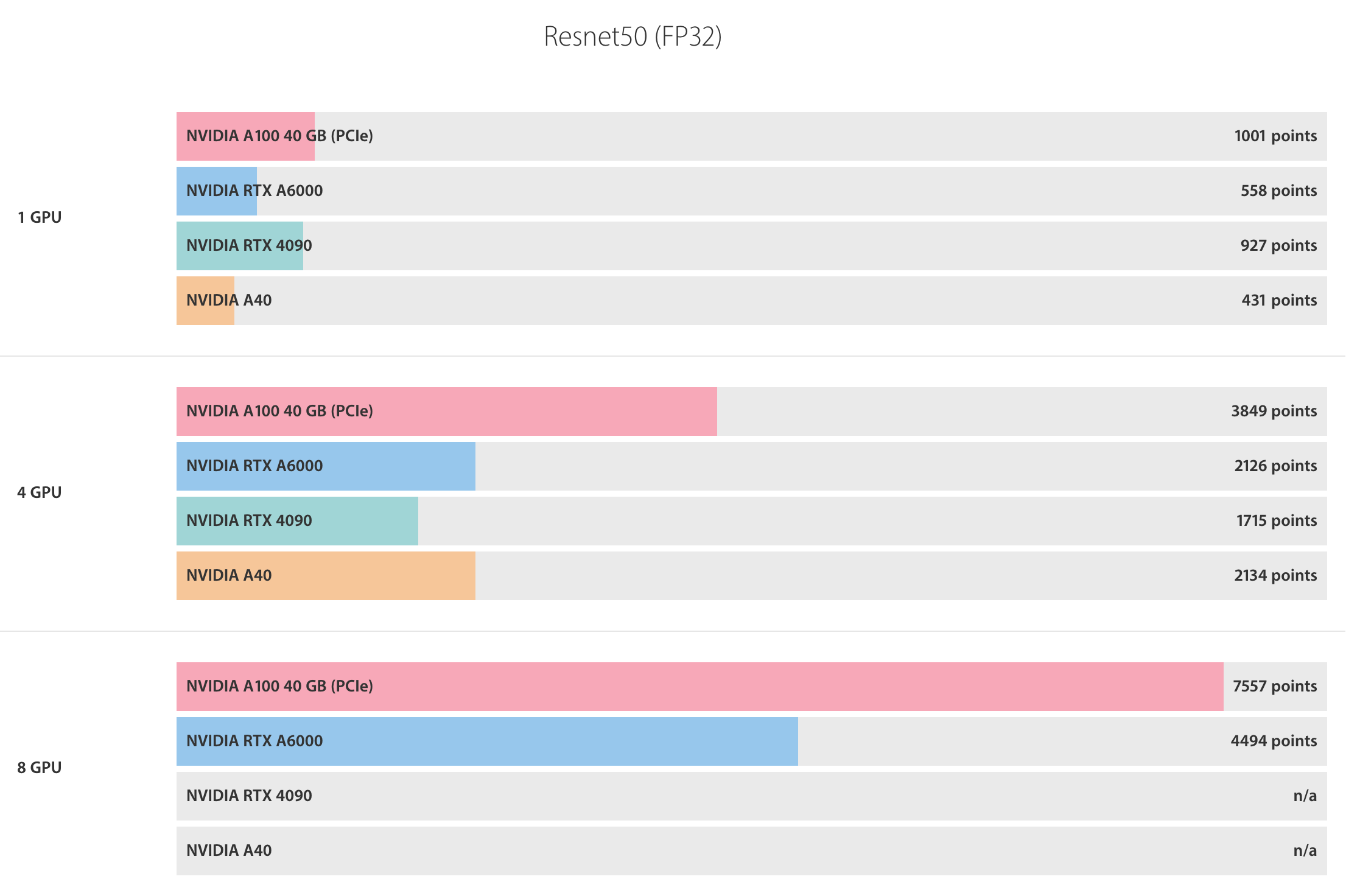
Les millors GPU per a l'aprenentatge profund, el desenvolupament d'IA, computen el 2023-2024. GPU i maquinari recomanats per a l'entrenament d'IA, inferència (LLM, IA generativa). Entrenament de GPU, punts de referència d'inferència mitjançant PyTorch, TensorFlow per a visió per computador (CV), PNL, text a veu, etc. Feu clic aquà per obtenir més informació >>
La targeta grĂ fica mĂ©s adequada per a l'aprenentatge profund depèn dels requisits especĂfics de la tasca. Per a tasques exigents que requereixen un alt rendiment, La NVIDIA A100 Ă©s la millor opciĂł. Per a tasques a mitjana escala, el RTX A6000 ofereix un bon equilibri de rendiment i cost. El RTX 4090 Ă©s una opciĂł adequada per a tasques o aficionats a petita escala. La NVIDIA V100 Ă©s una opciĂł rendible per a requisits moderats, mentre que La NVIDIA A40 Ă©s ideal per a tasques d'aprenentatge profund de nivell inicial.
| 1640: Festa del Pilar al 12 d'octubre per a descatalanitzar el descobriment i la Chiesa de Santa Maria in Monserrato |
| Caravela o calauera |
| Los Cresques, los Ferrer, los Colom y los Cabot |
| Bartomeu Mates |
| Crux gemmata |
| Betzoar - antiverĂ |
| Pel forat del pany.. BorbĂł o austracista? |
| La 1ÂŞ carta impresa de Colom ho fou en catalĂ (UNH5) |
| Mustang ve de mesteng |
| Obertura catalana |